Dreamitate formulates a visuomotor policy as video generation + 3D tracking, enabling much better generalization to unseen objects and environments.
Abstract
A key challenge in manipulation is learning a policy that can robustly generalize to diverse visual environments. A promising mechanism for learning robust policies is to leverage video generative models, which are pretrained on large-scale datasets of internet videos. In this paper, we propose a visuomotor policy learning framework that fine-tunes a video diffusion model on human demonstrations of a given task. At test time, we generate an example of an execution of the task conditioned on images of a novel scene, and use this synthesized execution directly to control the robot. Our key insight is that using common tools allows us to effortlessly bridge the embodiment gap between the human hand and the robot manipulator. We evaluate our approach on four tasks of increasing complexity and demonstrate that harnessing internet-scale generative models allows the learned policy to achieve a significantly higher degree of generalization than existing behavior cloning approaches.
Performance Evaluation

Rotating Unseen Objects
Scooping Unseen Materials Among Unseen Distractors
Sweeping Unseen Particles Among Unseen Distractors
Push Unseen Shape to Target
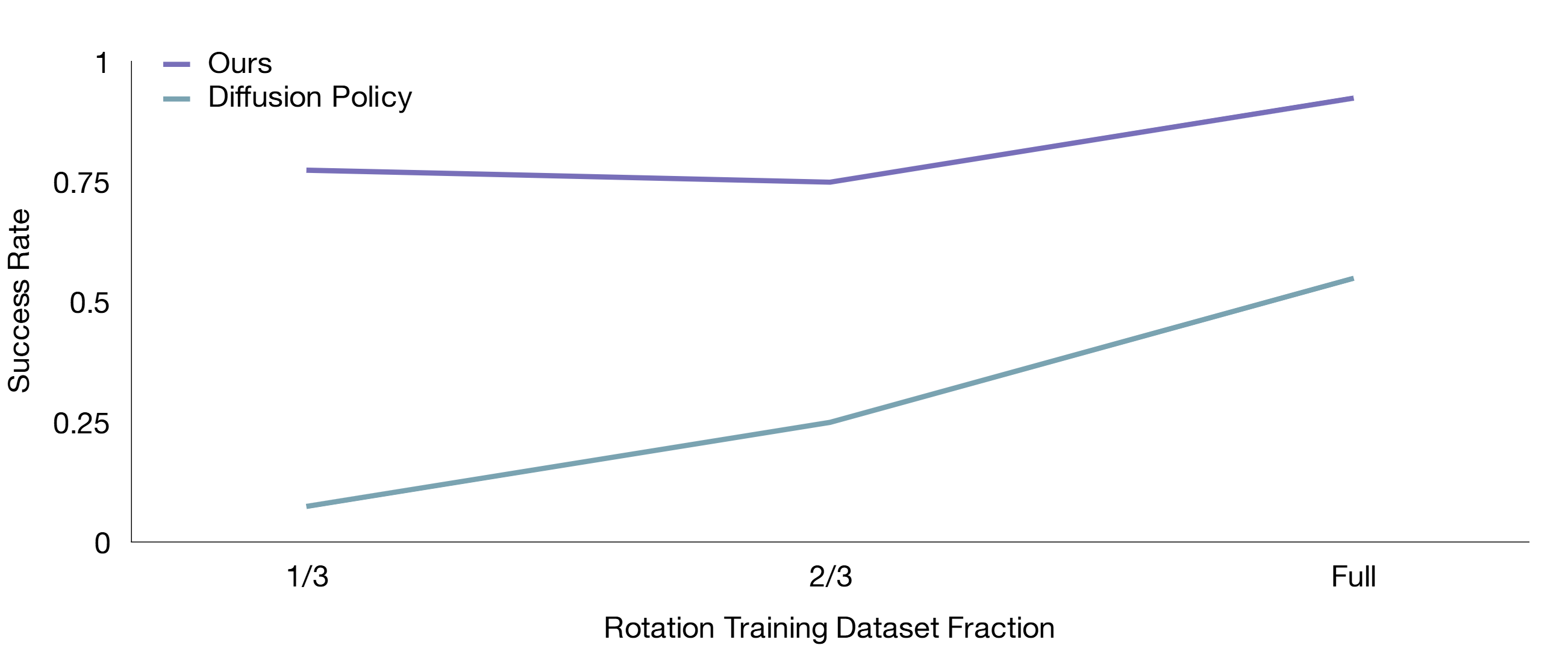
Performance Scaling Curve
All Evaluation Runs for Each Task (Uncurated)
BibTeX
@misc{liang2024dreamitate,
title={Dreamitate: Real-World Visuomotor Policy Learning via Video Generation},
author={Junbang Liang and Ruoshi Liu and Ege Ozguroglu and Sruthi Sudhakar and Achal Dave and Pavel Tokmakov and Shuran Song and Carl Vondrick},
year={2024},
eprint={2406.16862},
archivePrefix={arXiv},
primaryClass={id='cs.RO' full_name='Robotics' is_active=True alt_name=None in_archive='cs' is_general=False description='Roughly includes material in ACM Subject Class I.2.9.'}
}